Stage 01Signal inventory and governance

The "Run-to-Failure" debate begins. Since an asset is the primary throughput bottleneck, management is reluctant to shut down proactive maintenance without 100% certainty of the defect.
In operations, the drive to finish the shift often leads to catastrophic failure.
The goal is to identify failures in the Warning Phase (2-17% drift) to allow for replacement planning.
Stage 01Signal inventory and governance
Stage 02Data readiness and feature lineage

Stage 03Model development and validation

Stage 04Deployment and operational monitoring

Stage 05Decision thresholds and workflow fit

Stage 06Value tracking and model lifecycle

An illustrative drift sequence: vibration drift crosses the 2% warning threshold on day 7; leaving a planning window instead of an unplanned stop.
We combine live telemetry, history, and failure context so teams see drift before trips, downtime, or scrap hit the scorecard; moving from “what was the last reading?” to “how much runway do we have?”.
Deliverables stay in the forums you already run: trend and health, time-to-risk band, recommended actions, and traceable evidence the owner can stand behind in planning and maintenance.
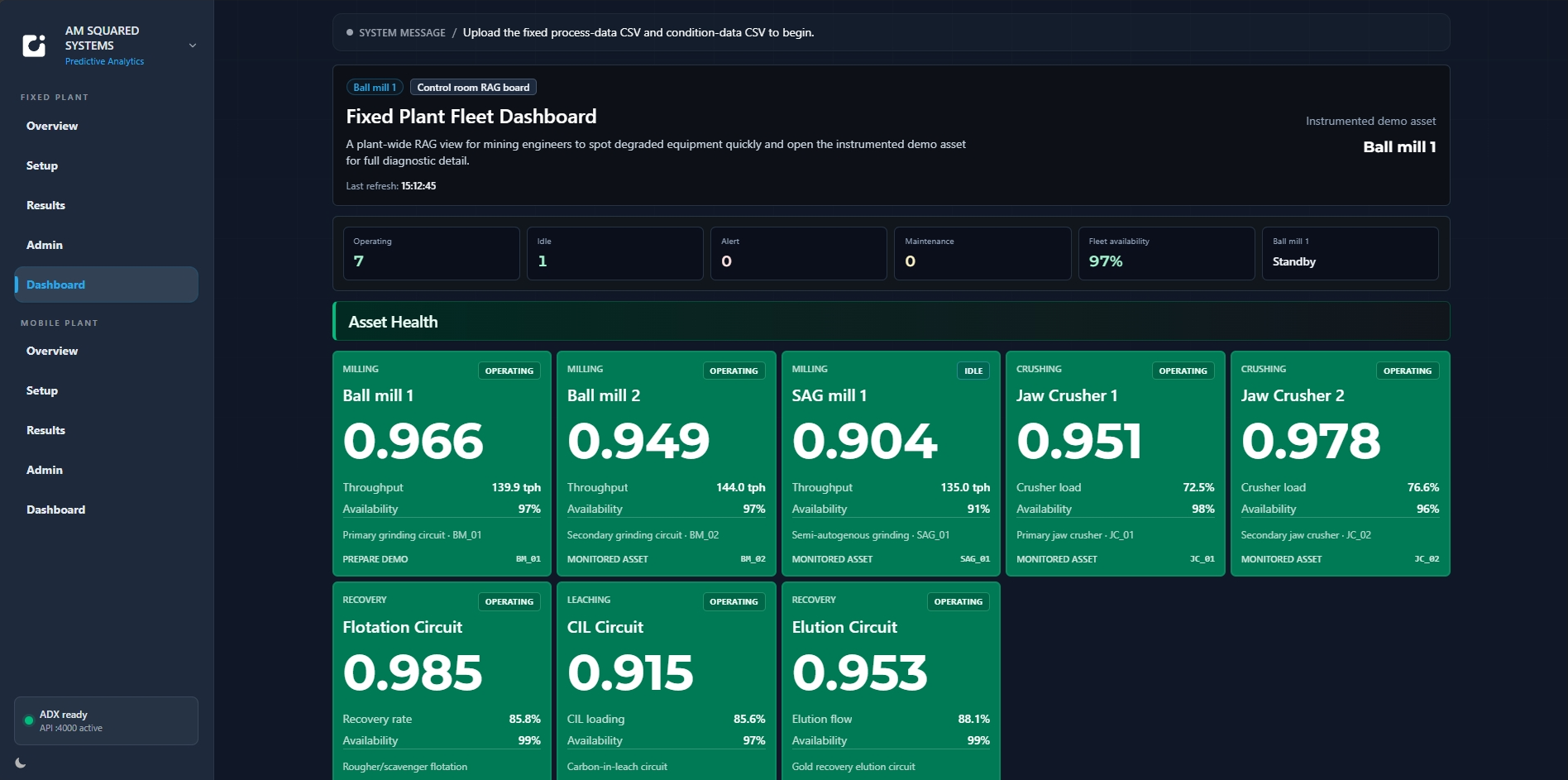
Discovery maps data readiness, stakeholder questions, and the first governed outputs worth piloting—so effort lines up with how your site actually decides.